The economy stopped rewarding knowledge retention. Dan Schipper named this shift the allocation economy: the valuable thing now is not what you can recall, but how well you can allocate resources (attention, compute, tools, and people) to the right sub-problems at the right time. Knowledge is cheap. It's everywhere. What isn't cheap is judgment about where to point it.
I've been building software for over 20 years. The shift I've watched happen in the last two years is not about models getting better at writing code. It's about what becomes possible when the cost of exploration drops to nearly zero. That changes what the valuable human in the loop is actually doing.
The Operator
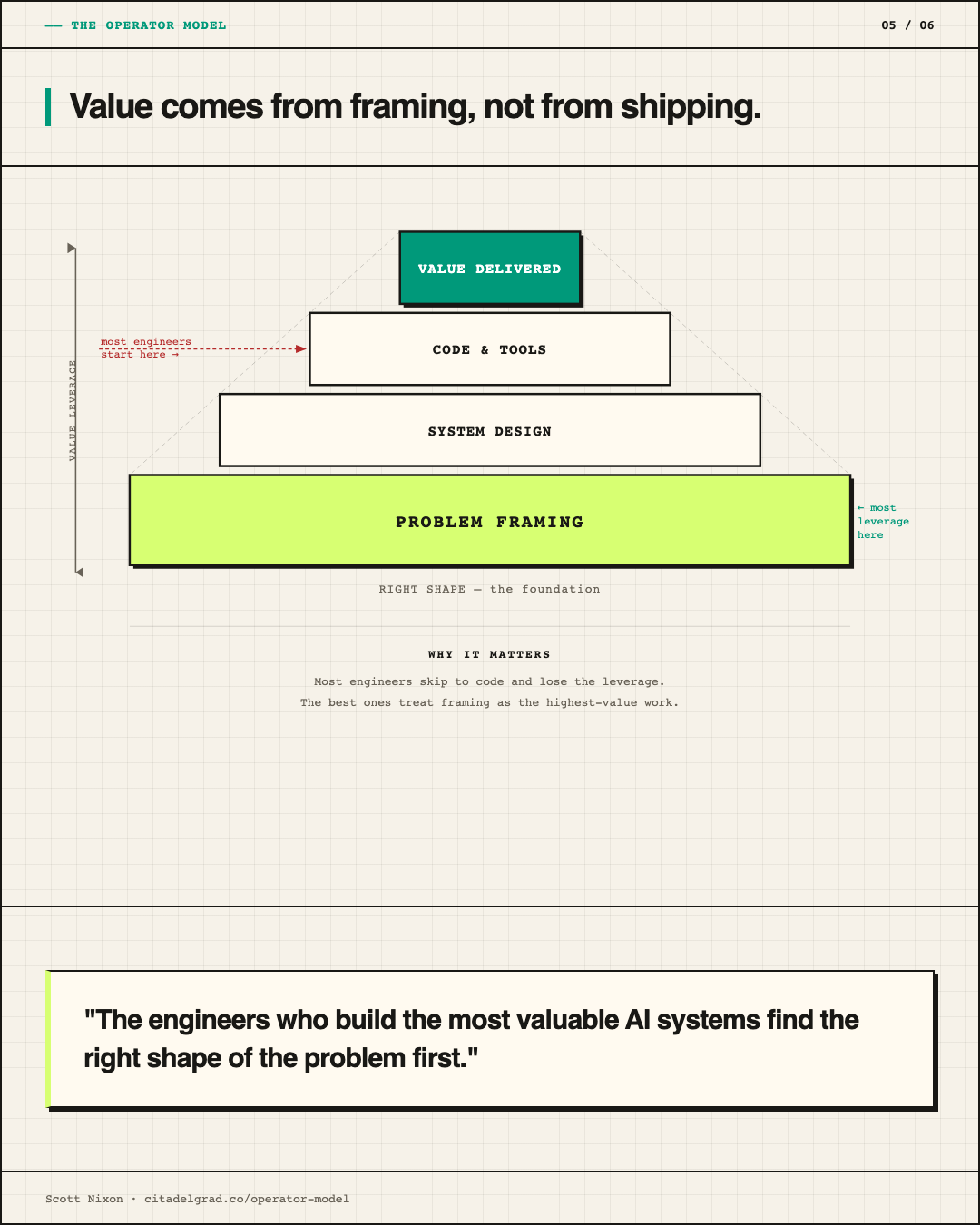
The Operator Model is my name for how I work. The operator's job is not implementation. It's compression.
When I get a new problem, the first thing I do is resist the urge to build. That impulse, the instinct to go straight to code, is expensive. It locks in a shape for the problem before you know if that shape is correct. Instead, I try to identify what kind of problem this is. Is it a routing problem? A classification problem? A UX problem dressed up as an infrastructure problem? Getting the shape wrong early is the most expensive mistake in software. Everything you build on top of a wrong model is waste.
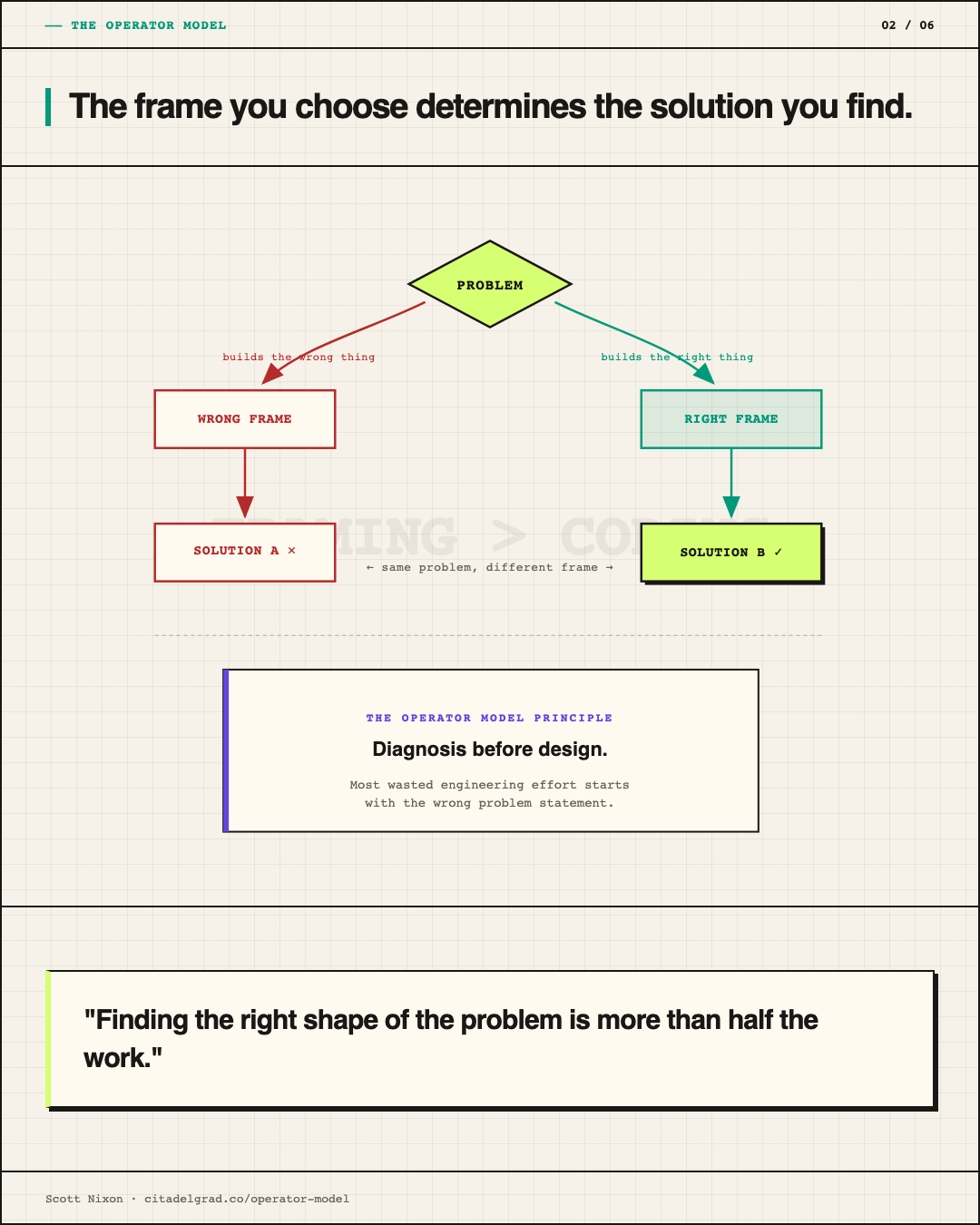
Once I have a hypothesis about the shape, I compress the search space. That means eliminating branches fast. Not open-ended research, but filtered research. What already exists that solves this? What violates my constraints without me having to investigate it deeply? What can I safely ignore? Intelligence is not knowing more. It's knowing what not to pursue. The intuition you build from shipping real products is a fast-path heuristic for that elimination process.
After compression, I allocate. Which part of this goes to an LLM? Which part needs a real database? Which part is a human judgment call that should not be automated? Allocation is the core skill. Then I step back and let the system run.
Find the shape, compress the space, allocate, step back.

How It Actually Works
In practice, the loop starts with pain.
I don't begin with hard requirements. I begin with a user story that describes something that hurts: "I don't want to babysit the agent," or "I need to see everything about a customer in one place." That pain becomes the filter for all subsequent research. Does this tool resolve the pain, or does it just move complexity around? The unix philosophy, composable tools that each do one thing, isn't a rule I follow because I read it in a book. It's the approach that fits the problem space I'm usually in. Principles should emerge from problem-fit, not be imported wholesale.
The decision framework I use is probabilistic, not optimal. Software is either around for less than a year or for ten years. Given that, and given how cheap AI makes course correction, early architecture decisions don't need to be optimal. They need to avoid catastrophic tail risks. The threshold for "good enough" has collapsed. Spend less time searching for the perfect choice and more time preserving the ability to correct course.
One thing the framework depends on that doesn't get talked about enough: exploratory software. Before a workflow can be meaningfully automated, you often need several iterations of applications, interfaces, and data structures, built and discarded, just to understand the problem well enough to automate it correctly. This is not waste. It is the research process. The operator's skill is recognizing when you've done enough exploration to commit to a specific shape. That's a judgment call, not a formula.
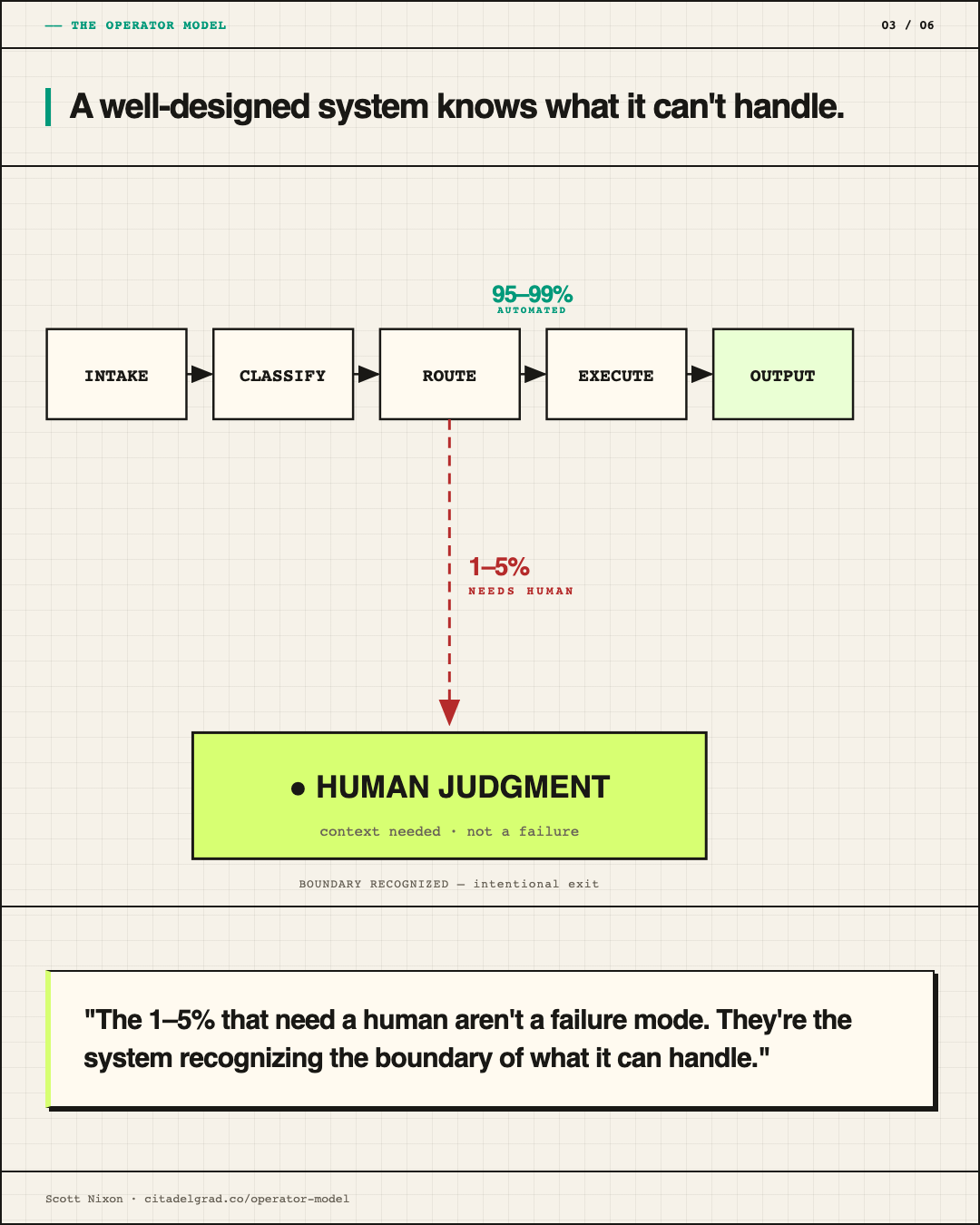
The other piece is specificity. Effective automation is not generalized across a problem domain. The old model was: automate to 50 to 70 percent coverage, put humans in to manage the gaps. The new model: build processes specific enough that humans are only needed when the problem is genuinely too complex for the system, somewhere between 1 and 5 percent of cases. Humans handle exceptional complexity, not routine gap-filling.
What This Looks Like Shipped
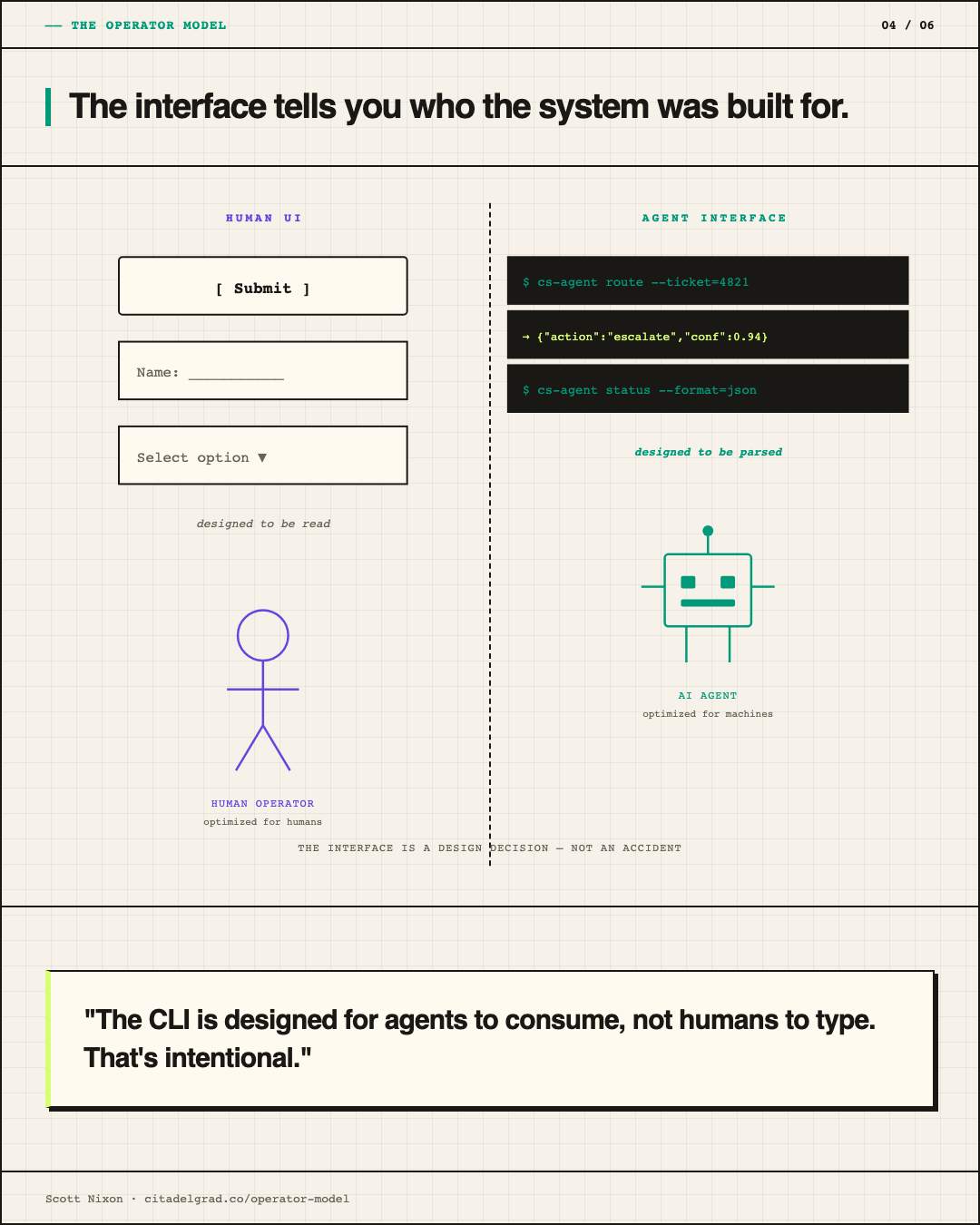
cs-agent is the clearest recent example. Meal Mentor gets roughly 12 non-customer emails per day from customers of a European company with the same name. The naive solution is a human triaging each one. The wrong AI solution is a general-purpose agent with tools and a prompt telling it to figure it out.
I built a classifier, not an agent. DSPy on GCP Agent Engine, Gemini Flash as the underlying model, Terraform for the infrastructure. Three-class output: not-customer gets an auto-reply, uncertain gets a Gmail tag that routes to CS review, customer goes to normal flow. Confidence thresholds are baked in because the system should not guess when it doesn't know. Every scheduled run sends a summary email to support and to me. That last part is observability, not a feature. I want to see what the classifier is doing so I can catch drift before it becomes a problem. The shape of the problem was classification with a human on the loop for uncertainty. Getting that shape right early meant the implementation was straightforward.
Where It Comes From
Product intuition is not something you can shortcut. It comes from shipping real products to real users and watching how they actually use them. I have that from over 20 years of building, including running the technical side of Happy Herbivore and Meal Mentor, consumer products with real customers paying real money. You learn to feel the compound cost of small friction. One option buried two menus deep, done 50 times a day, is a real tax on the people doing that work.
That felt understanding of user pain is what lets me start from pain rather than requirements. It also produced the unified CS dashboard I shipped for Happy Herbivore back in 2013: a single profile view aggregating Stripe, PayPal, fulfillment, Gmail, and Help Scout that let one CS person handle 30 to 50 emails a day and 200 on sale days without needing accounts in every underlying system. The Operator Model, single-pane-of-glass, automation specific to the job: those were working principles more than a decade before large language models made them easy to execute at scale.
Where the Model Struggles
I have ADHD. Reloading project context after an interruption costs me 10 to 15 minutes I often can't afford. Under cognitive load I take shortcuts. I miss linting. I don't fully reload state. I write code that works but assumes context that isn't written down anywhere. That's a real failure mode.
The response I've built to it is to externalize state. CI catches the lint I skip. Foundry, the local autonomous CI and build system I'm building, surfaces status without requiring me to reconstruct it from memory. The single-pane-of-glass is not an aspiration. It is a coping mechanism that became a design principle. The need for everything in one place, born from the fragmentation cost of context switching, is the same impulse that produced the Happy Herbivore CS dashboard, the autonomous developer stack, and Foundry. The tools are compensations that became products.
The other weakness is scatter. New ideas, new opportunities, interesting problems on the horizon pull attention away from in-progress work. This is the primary source of unfinished projects. Not inability. Interest migration. What I have against it is a GTD practice that forces every to-do to be a concrete next physical action rather than a project title, and a bias toward logging things in the issue tracker before following them anywhere.
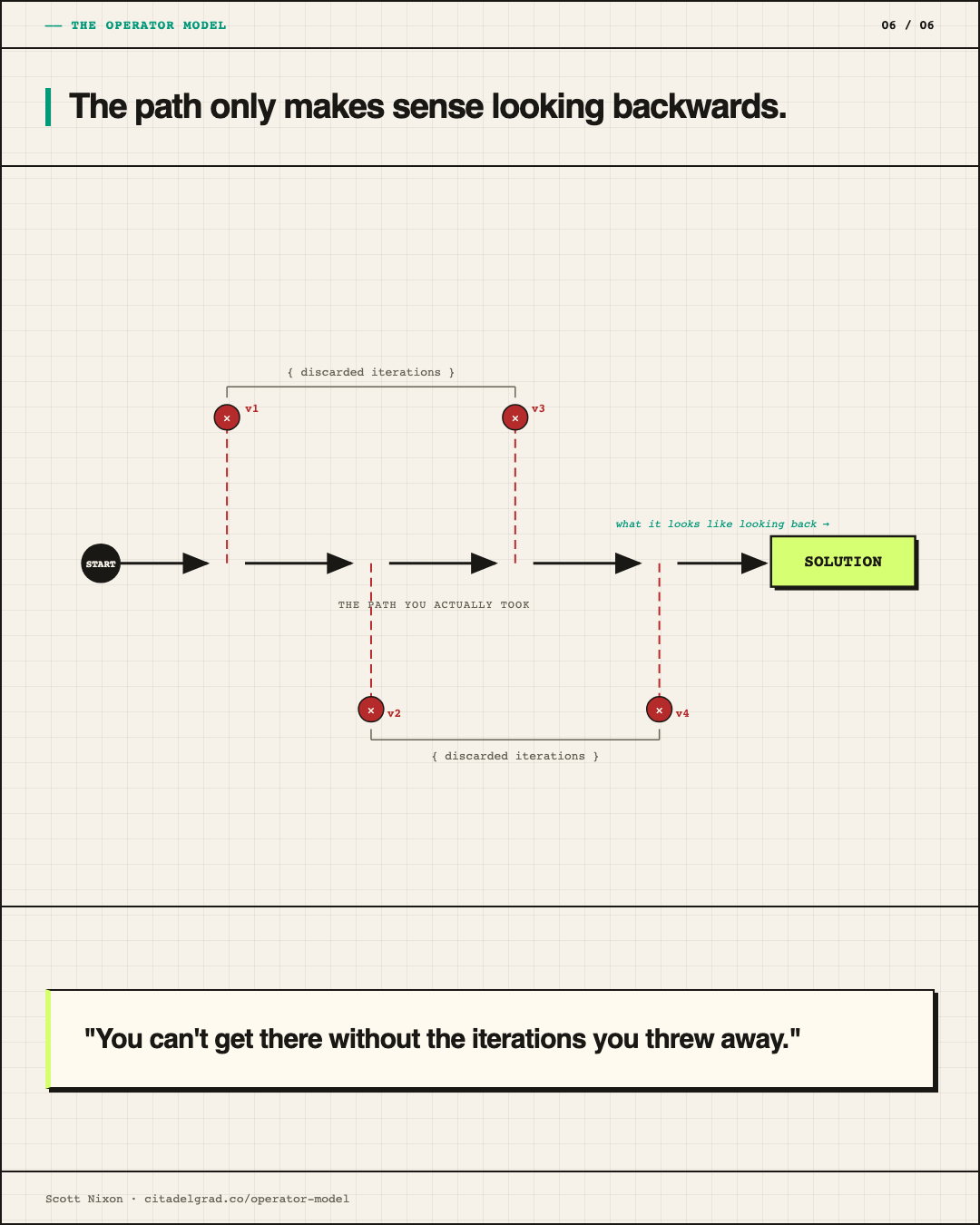
The hardest failure mode in the model itself is misdiagnosing the shape of a problem early. If I'm wrong about what kind of problem I'm looking at, everything downstream is built on that mistake. Compression is fast but it isn't foolproof. I've shipped classifiers when I needed routers. I've built automation for workflows that turned out to be discovery problems first. The cost of a wrong shape diagnosis compounds, because the operator's whole job is to allocate correctly from that diagnosis. The best defense is keeping early iterations cheap so the cost of discarding them stays low.
Why This Matters Now
The Operator Model existed before LLMs. I was practicing it in 2013. But it didn't scale before because the cost of exploration was too high. Each iteration of exploratory software required significant implementation time. Compressing to the right shape of a problem still required building things in order to learn what was actually buildable.
AI collapses the cost of exploration. That is the actual economic change, not that it replaces the operator's judgment about what shape a problem has. It makes it cheap to test that judgment quickly. You can run three different approaches in a day and throw two away. The iteration-discard cycle that used to be expensive is now nearly free.
That changes what's worth building. Problems that weren't worth automating before, because the friction was too high relative to the payoff, are now obvious targets. The operator's job expands because the surface area of what's worth doing expands with it.
The Hiring Argument
The interview question that doesn't get asked enough is not "have you done X before?" It is: when you encountered a problem you'd never seen, how fast did you find the right shape of it, and how accurately did you allocate resources to solve it?
The operator's value is not in the X. It's in the loop that produced the correct X. An engineer who has shipped one specific thing well is not the same as an engineer who can rapidly find what needs shipping and route the right tools and people to build it. The former is a specialist. The latter is the person you need when the problem space itself is uncertain, which is the condition most organizations are actually operating in right now.
The question worth asking is whether someone can compress fast and allocate well, because those are the skills that determine whether a team builds the right thing, not just something that works.